插入排序、选择排序、归并排序等等,这些算法都属于内部排序算法,即排序的整个过程*只是在内存*中完成。而当待排序的文件比内存的可使用容量还大时,文件无法一次性放到内存中进行排序,需要借助于外部存储器(例如硬盘、U盘、光盘),这时就需要用到本章介绍的外部排序算法来解决。
外部排序算法由两个阶段构成:
- 按照内存大小,将大文件分成若干长度为
B的子文件(B应小于内存的可使用容量),然后将各个子文件依次读入内存,使用适当的内部排序算法对其进行排序(排好序的子文件统称为“归并段”或者“顺段”),将排好序的归并段重新写入外存,为下一个子文件排序腾出内存空间; - 对得到的顺段进行合并,直至得到整个有序的文件为止。
例如,有一个含有 10000 个记录的文件,但是内存的可使用容量仅为 1000 个记录,毫无疑问需要使用外部排序算法,具体分为两步:
- 将整个文件其等分为 10 个临时文件(每个文件中含有 1000 个记录),然后将这 10 个文件依次进入内存,采取适当的内存排序算法对其中的记录进行排序,将得到的有序文件(初始归并段)移至外存。
- 对得到的 10 个初始归并段进行如图 1 的两两归并,直至得到一个完整的有序文件。
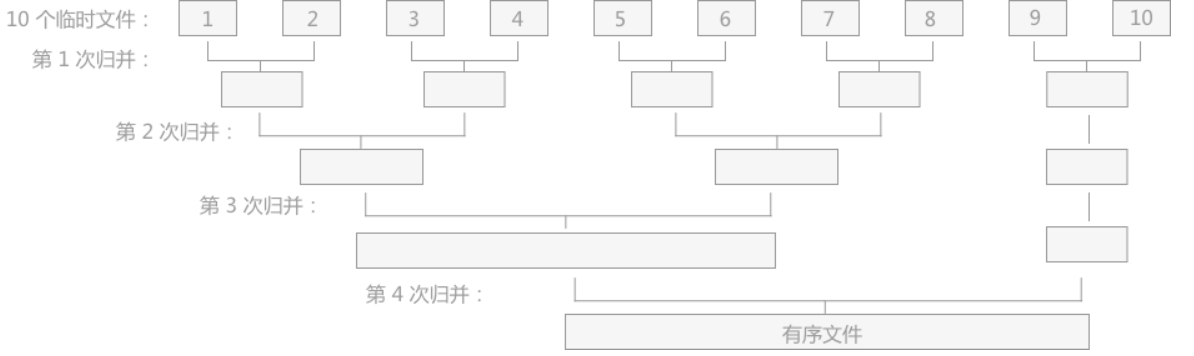
如上图所示有 10 个初始归并段到一个有序文件,共进行了 4 次归并,每次都由 m 个归并段得到 ⌈m/2⌉ 个归并段,这种归并方式被称为 2-路平衡归并。
注意:在实际归并的过程中,由于内存容量 的限制不能满足同时将 2 个归并段全部完整的读入内存进行归并,只能不断地取 2 个归并段中的每一小部分进行归并,通过不断地读数据和向外存写数据,直至 2 个归并段完成归并变为 1 个大的有序文件。
对于外部排序算法来说,影响整体排序效率的因素主要取决于读写外存的次数,即访问外存的次数越多,算法花费的时间就越多,效率就越低。
计算机中处理数据的为中央处理器(CPU),如若需要访问外存中的数据,只能通过将数据从外存导入内存,然后从内存中获取。同时由于内存读写速度快,外存读写速度慢的差异,更加影响了外部排序的效率。
对于同一个文件来说,对其进行外部排序时访问外存的次数同归并的次数成正比,即归并操作的次数越多,访问外存的次数就越多。图 1 中使用的是 2-路平衡归并的方式,举一反三,还可以使用 3-路归并、4-路归并甚至是 10-路归并的方式,下图为 5-路归并的方式:

对比两个图可以看出,对于 k-路平衡归并中 k 值的选择,增加 k 可以减少归并的次数,从而减少外存读写的次数,最终达到提高算法效率的目的。除此之外,一般情况下对于具有 m 个初始归并段进行 k-路平衡归并时,归并的次数为:
\(s=log_km\)
其中 s 表示归并次数。
从公式上可以判断出, 想要达到减少归并次数从而提高算法效率的目的,可以从两个角度实现:
- 增加 k-路平衡归并中的 k 值;
- 尽量减少初始归并段的数量 m,即增加每个归并段的容量;
其增加 k 值的想法引申出了一种外部排序算法:多路平衡归并算法;增加数量 m 的想法引申出了另一种外部排序算法:置换-选择排序算法。两种外部排序算法会在后序章节中详细介绍。
败者树
通过上一节对于外部排序的介绍得知:对于外部排序算法来说,其直接影响算法效率的因素为读写外存的次数,即次数越多,算法效率越低。若想提高算法的效率,即减少算法运行过程中读写外存的次数,可以增加 k –路平衡归并中的 k 值。
但是经过计算得知,如果毫无限度地增加 k 值,虽然会减少读写外存数据的次数,但会增加内部归并的时间,得不偿失。
例如在上节中,对于 10 个临时文件,当采用 2-路平衡归并时,若每次从 2 个文件中想得到一个最小值时只需比较 1 次;而采用 5-路平衡归并时,若每次从 5 个文件中想得到一个最小值就需要比较 4 次。以上仅仅是得到一个最小值记录,如要得到整个临时文件,其耗费的时间就会相差很大。
为了避免在增加 k 值的过程中影响内部归并的效率,在进行 k-路归并时可以使用“败者树”来实现,该方法在增加 k 值时不会影响其内部归并的效率。
败者树实现内部归并
败者树是树形选择排序的一种变形,本身是一棵完全二叉树。
在树形选择排序一节中,对于无序表{49,38,65,97,76,13,27,49}创建的完全二叉树如下图所示,构建此树的目的是选出无序表中的最小值。
这棵树与败者树正好相反,是一棵“胜者树”。因为树中每个非终端结点(除叶子结点之外的其它结点)中的值都表示的是左右孩子相比较后的较小值(谁最小即为胜者)。例如叶子结点 49 和 38 相对比,由于 38 更小,所以其双亲结点中的值保留的是胜者 38。然后用 38 去继续同上层去比较,一直比较到树的根结点。
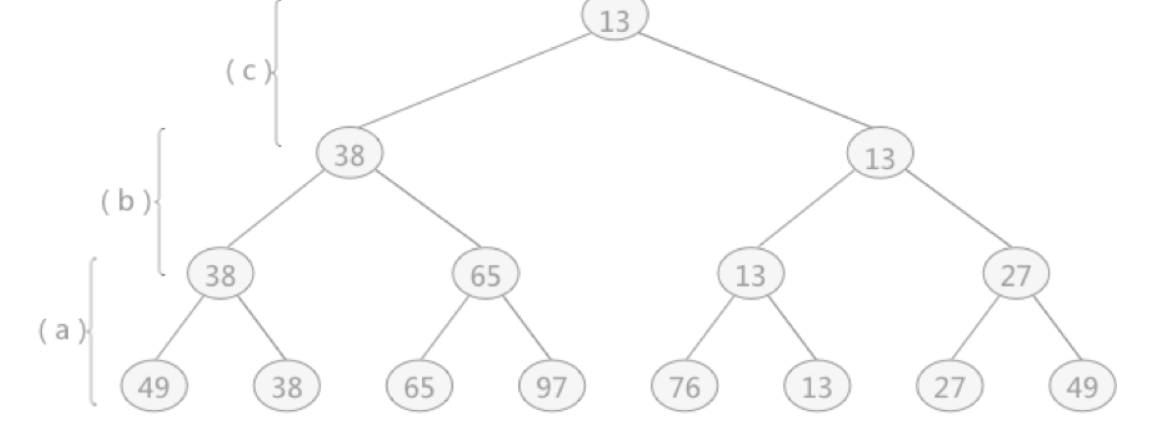
而败者树恰好相反,其双亲结点存储的是左右孩子比较之后的失败者,而胜利者则继续同其它的胜者去比较。
上图中,叶子结点 49 和 38 比较,38 更小,所以 38 是胜利者,49 为失败者,但由于是败者树,所以其双亲结点存储的应该是 49;同样,叶子结点 65 和 97 比较,其双亲结点中存储的是 97 ,而 65 则用来同 38 进行比较,65 会存储到 97 和 49 的双亲结点的位置,38 继续做后续的胜者比较,依次类推。
胜者树和败者树的区别就是:胜者树中的非终端结点中存储的是胜利的一方;而败者树中的非终端结点存储的是失败的一方。而在比较过程中,都是拿胜者去比较。
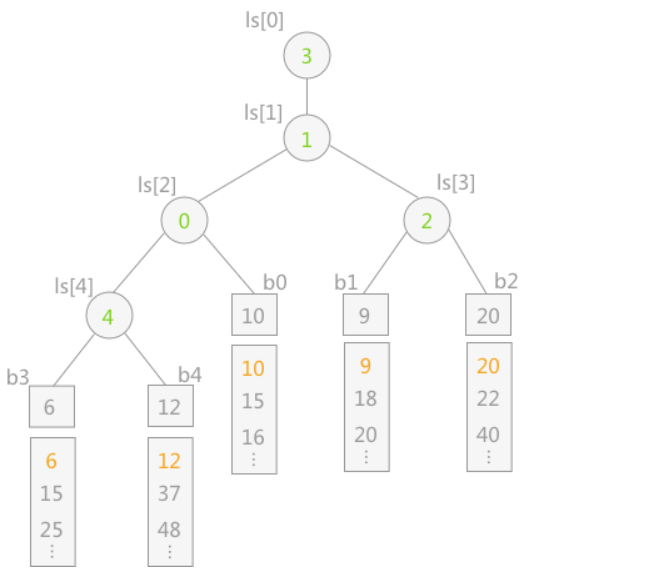
如上图所示为一棵 5-路归并的败者树,其中 b0—b4 为树的叶子结点,分别为 5 个归并段中存储的记录的关键字。ls 为一维数组,表示的是非终端结点,其中存储的数值表示第几归并段(例如 b0 为第 0 个归并段)。ls[0] 中存储的为最终的胜者,表示当前第 3 归并段中的关键字最小。
当最终胜者判断完成后,只需要更新叶子结点 b3 的值,即导入关键字 15,然后让该结点不断同其双亲结点所表示的关键字进行比较,败者留在双亲结点中,胜者继续向上比较。
例如,叶子结点15先同其双亲结点 ls[4] 中表示的 b4 中的 12 进行比较,12 为胜利者,则 ls[4] 改为 15,然后 12 继续同 ls[2] 中表示的 10 做比较,10 为胜者,然后 10 继续同其双亲结点 ls[1] 表示的 b1(关键字 9)作比较,最终 9 为胜者。整个过程如下图所示:
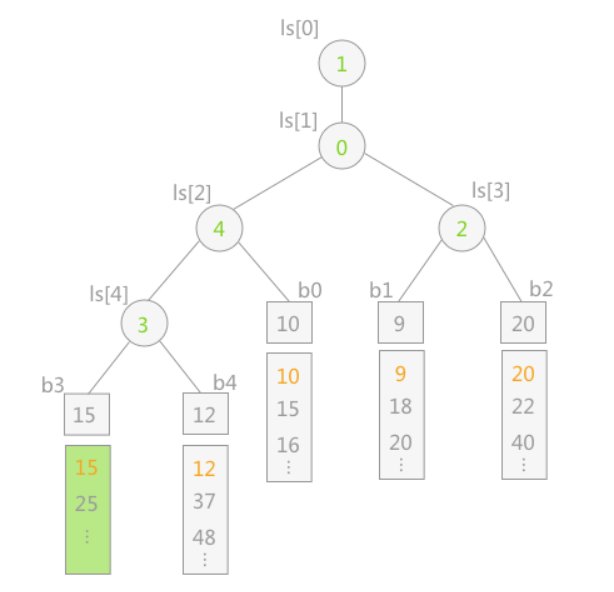
注意:为了防止在归并过程中某个归并段变为空,处理的办法为:可以在每个归并段最后附加一个关键字为最大值的记录。这样当某一时刻选出的冠军为最大值时,表明 5 个归并段已全部归并完成。(因为只要还有记录,最终的胜者就不可能是附加的最大值)
##